3 min to read
#100DaysOfNLP Day 6: Preliminary Analysis of Gendered Dialogue in Movies
On Day 6 of my 100 Days Of NLP journey I start analyzing movie lines and looking at differences in speech between male and female characters.
Day 6 of my 100 Days of Natural Language Processing journey, my research partner and I began to work on doing preliminary statistical analysis and continued preprocessing our dataset: the Cornell Movie-Dialogs Corpus. This work mainly involved Parts of Speech tagging and Named Entity recognition tagging our dataset and making plots of the average length of utterances (dialogue lines) based on gender. I’ll outline the work we did and the general process we went through to get our results. Of course if you want to look at the exact code we used, it is all on this github repository.
Goals for the Day:
As you saw in the paragraph above, our main goals for the day were to POS tag the text data we collected divided by gender, NER tag the text data we collected divided by gender, and look at the average length of utterances spoken by characters divided by gender. The next few sections of the post will show just exactly how we achieved these goals.
Parts of Speech Tagging:
For those who don’t do NLP, Parts of Speech tagging is just associating every word in a text with the part of speech it is, this is part of collecting as much information about the data as we can. In order to parts of speech tag our text and do anything else we wanted for the day, we had to create text files that contained all the lines from the dataset that were seperated by gender. Essentially, we just looped through the collated_data.txt file and based on the gender characteristic of the line, we put the line of text into a text file that was either male_text.txt, female_text.txt, or genderless_text.txt (unknown gender). Once that was done with a simple python script, I moved into POS tagging each of the text files. In order to do that I read each file individually with python, then word tokenized each of the text files and then used the NLTK python library to parts of speech tag the individual files. We then wrote these POS tagged lines to text files that were separated by gender.
Named Entity Recognition Tagging:
Named Entity Recognition is also an important part of NLP, knowing what named entities are present in a text can provide a lot of insight into the data you have. Just like with POS tagging we used the gendered text files that we created and then tokenized the data before we began to recognize the named entities present in each of the gendered text files. To actually do the NER tagging, we used NLTK’s built in NER function that allowed us to properly NER tag the data. Once this part of our work was done we moved on to looking at the average length of utterances delivered by characters.
Primary Analysis:
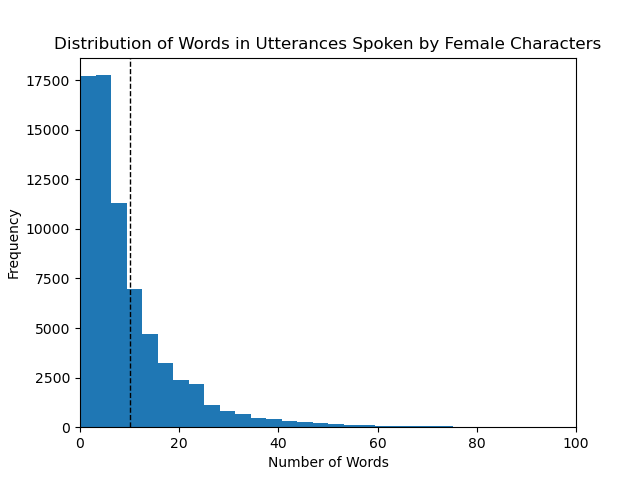
Finding out the average length of utterances and difference in between male and female characters was fairly easy, but getting to it took a long time due to how long it took for the POS and NER tagging to be fine tuned and run on my PC. This was done with a simple python script that looped through every line in the gender separated text files and counted the number of words in each line and then calculating the average number of words per line in each of the files. Our results are presented in the graphs below.
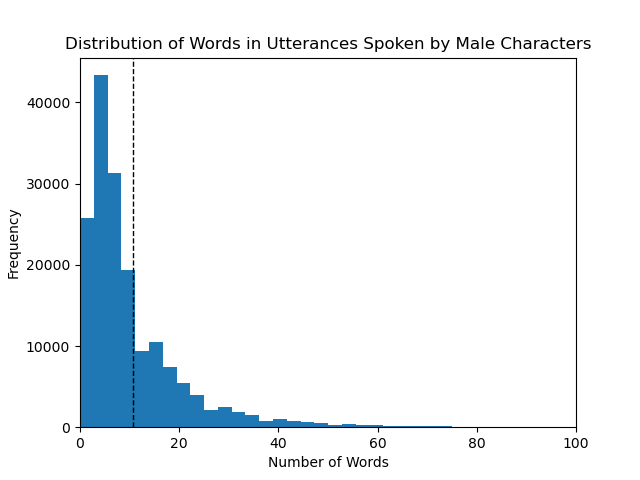
For the male characters we can see the average number of words in an utterance is around 10, with the majority being in between 1 and 20 and a few outliers in the 40 - 80 word region.
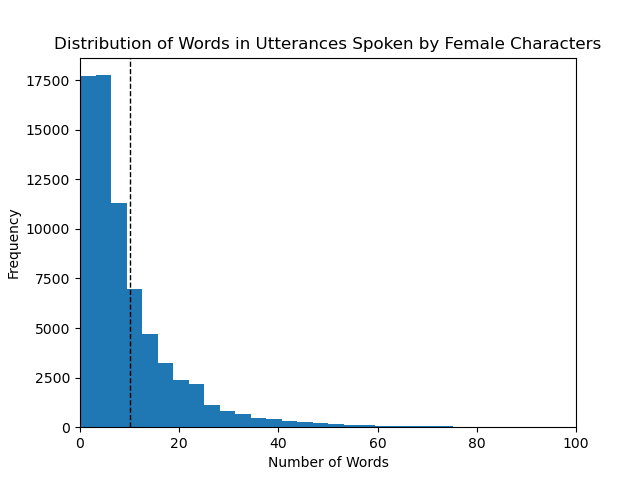
For the female characters the average is also around 10 words with a larger portion of the female utterances having lengths below 10 as compared to utterances delivered by male characters.
This is fairly interesting data, but there isn’t a lot we can learn from it as of right now, however tomorrow’s work centers around graphing POS tags, NER tags, and the sentiment of the lines delivered.

Comments